基于这个问题,推荐我厂范欣欣同学的一篇文章,这篇文章笔者将会分别针对OpenTSDB、Druid、InfluxDB以及Beringei这四个时序系统中的时序数据模型设计进行介绍。希望对题主有所帮助,原文如下:
时序数据库技术体系中一个非常重要的技术点是时序数据模型设计,不同的时序系统有不同的设计模式,而不同的设计模式对时序数据的读写性能、数据压缩效率等各个方面都有非常重要的影响。这篇文章笔者将会分别针对OpenTSDB、Druid、InfluxDB以及Beringei这四个时序系统中的时序数据模型设计进行介绍。
在详细介绍时序数据模型之前,还是有必要简单回顾一下时序数据的几个基本概念,如下图所示:
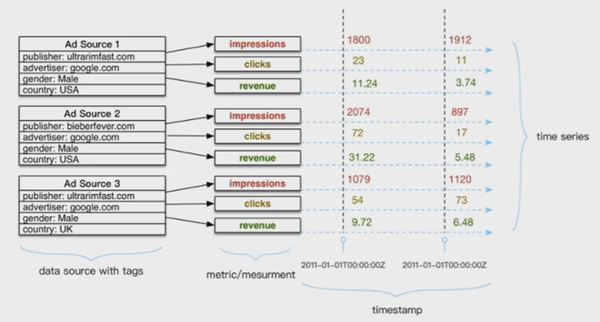
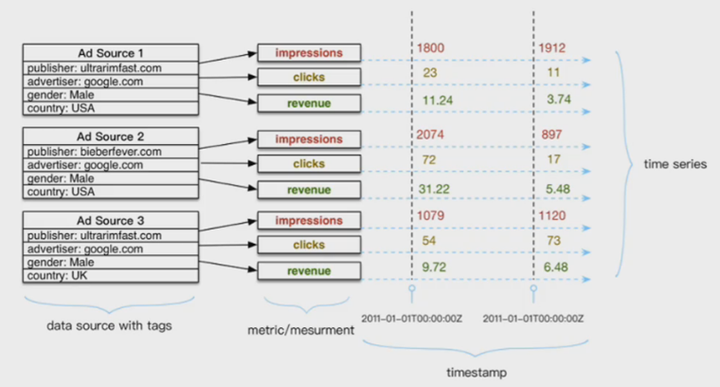
上图是一个典型的时序数据示意图,由图中可以看出,时序数据由两个维度坐标来表示,横坐标表示时间轴,随着时间的不断流逝,数据也会源源不断地吐出来;和横坐标不同,纵坐标由两种元素构成,分别是数据源和metric,数据源由一系列的标签(tag,也称为维度)唯一表示,图中数据源是一个广告数据源,这个数据源由publisher、advertiser、gender以及country四个维度值唯一表示,metric表示待收集的数据源指标。一个数据源通常会采集很多指标(metric),上图中广告数据源就采集了impressions、clicks以及revenue这三种指标,分别表示广告浏览量、广告点击率以及广告收入。
看到这里,相信大家对时序数据已经有了一个初步的了解,可以简单的概括为:一个时序数据点(point)由datasource(tags)+metric+timestamp这三部分唯一确定。然而,这只是逻辑上的概念理解,那具体的时序数据库到底是如何将这样一系列时序数据点进行存储的呢?下文笔者针对OpenTSDB、Druid、InfluxDB以及Beringei四种系统进行介绍。
OpenTSDB(HBase)时序数据存储模型
OpenTSDB基于HBase存储时序数据,在HBase层面设计RowKey规则为:metric+timestamp+datasource(tags)。HBase是一个KV数据库,一个时序数据(point)如果以KV的形式表示,那么其中的V必然是point的具体数值,而K就自然而然是唯一确定point数值的datasource+metric+timestamp。这种规律不仅适用于HBase,还适用于其他KV数据库,比如Kudu。
既然HBase中K是由datasource、metric以及timestamp三者构成,现在我们可以简单认为rowkey就为这三者的组合,那问题来了:这三者的组合顺序是怎么样的呢?
首先来看哪个应该排在首位。因为HBase中一张表的数据组织方式是按照rowkey的字典序顺序排列的,为了将同一种指标的所有数据集中放在一起,HBase将将metric放在了rowkey的最前面。假如将timestamp放在最前面,同一时刻的数据必然会写入同一个数据分片,无法起到散列的效果;而如果将datasource(即tags)放在最前面的话,这里有个更大的问题,就是datasource本身由多个标签组成,如果用户指定其中部分标签查找,而且不是前缀标签的话,在HBase里面将会变成大范围的扫描过滤查询,查询效率非常之低。举个上面的例子,如果将datasource放在最前面,那rowkey就可以表示为publisher=ultrarimfast.com&advertiser:google.com&gender:Male&country:USA_impressions_20110101000000,此时用户想查找20110101000000这个时间点所有发布在USA的所有广告的浏览量,即只根据country=USA这样一个维度信息查找指定时间点的某个指标,而且这个维度不是前缀维度,就会扫描大量的记录进行过滤。
确定了metric放在最前面之后,再来看看接下来应该将datasource放在中间呢还是应该将timestamp放在中间?将metric放在前面已经可以解决请求均匀分布(散列)的要求,因此HBase将timestamp放在中间,将datasource放在最后。试想,如果将datasource放在中间,也会遇到上文中说到的后缀维度查找的问题。
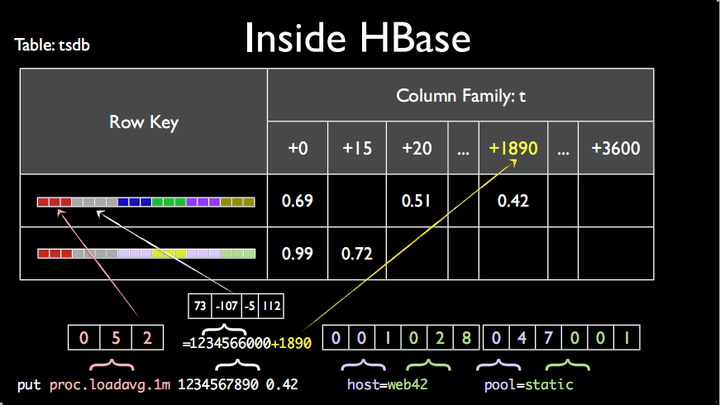
因此,OpenTSDB中rowkey的设计为:metric+timestamp+datasource,好了,那HBase就可以只设置一个columnfamily和一个column。那问题来了,OpenTSDB的这种设计有什么问题?在了解设计问题之前需要简单看看HBase在文件中存储KV的方式,即一系列时序数据在文件、内存中的存储方式,如下图所示:
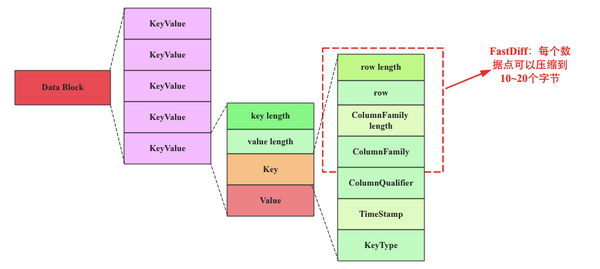
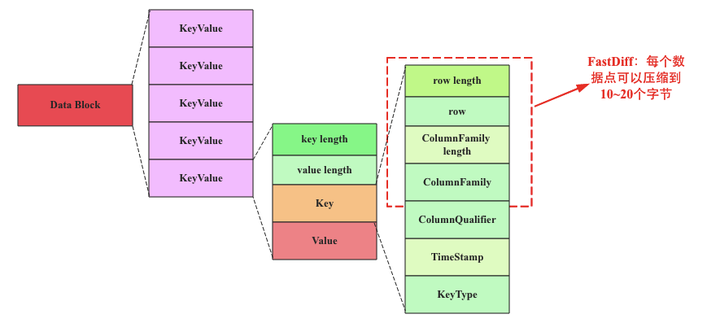
上图是HBase中一个存储KeyValue(KV)数据的数据块结构,一个数据块由多个KeyValue数据组成,在我们的事例中KeyValue就是一个时序数据点(point)。其中Value结构很简单,就是一个数值。而Key就比较复杂了,由rowkey+columnfamily+column+timestamp+keytype组成,其中rowkey等于metric+timestamp+datasource。
问题一:存在很多无用的字段。一个KeyValue中只有rowkey是有用的,其他字段诸如columnfamily、column、timestamp以及keytype从理论上来讲都没有任何实际意义,但在HBase的存储体系里都必须存在,因而耗费了很大的存储成本。
问题二:数据源和采集指标冗余。KeyValue中rowkey等于metric+timestamp+datasource,试想同一个数据源的同一个采集指标,随着时间的流逝不断吐出采集数据,这些数据理论上共用同一个数据源(datasource)和采集指标(metric),但在HBase的这套存储体系下,共用是无法体现的,因此存在大量的数据冗余,主要是数据源冗余以及采集指标冗余。
问题三:无法有效的压缩。HBase提供了块级别的压缩算法-snappy、gzip等,这些通用压缩算法并没有针对时序数据进行设置,压缩效率比较低。HBase同样提供了一些编码算法,比如FastDiff等等,可以起到一定的压缩效果,但是效果并不佳。效果不佳的主要原因是HBase没有数据类型的概念,没有schema的概念,不能针对特定数据类型进行特定编码,只能选择通用的编码,效果可想而知。
问题四:不能完全保证多维查询能力。HBase本身没有schema,目前没有实现倒排索引机制,所有查询必须指定metric、timestamp以及完整的tags或者前缀tags进行查询,对于后缀维度查询也勉为其难。
虽说有这样那样的问题,但是OpenTSDB还是针对存储模型做了两个方面的优化:
优化一:timestamp并不是想象中细粒度到秒级或毫秒级,而是精确到小时级别,然后将小时中每一秒设置到列上。这样一行就会有3600列,每一列表示一小时的一秒。这样设置据说可以有效的取出一小时整的数据。
优化二:所有metrics以及所有标签信息(tags)都使用了全局编码将标签值编码成更短的bit,减少rowkey的存储数据量。上文分析HBase这种存储方式的弊端是说道会存在大量的数据源(tags)冗余以及指标(metric)冗余,有冗余是吧,那我就搞个编码,将string编码成bit,尽最大努力减少冗余。虽说这样的全局编码可以有效降低数据的存储量,但是因为全局编码字典需要存储在内存中,因此在很多时候(海量标签值),字典所需内存都会非常之大。
上述两个优化可以参考OpenTSDB这张经典的示意图:

Druid时序数据存储模型设计
和HBase和Kudu这类KV数据库不同,Druid是另一种玩法。Druid是一个不折不扣的列式存储系统,没有HBase的主键。上述时序数据在Druid中表示是下面这个样子的:
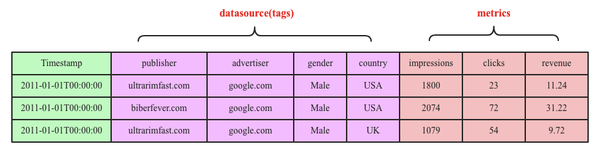
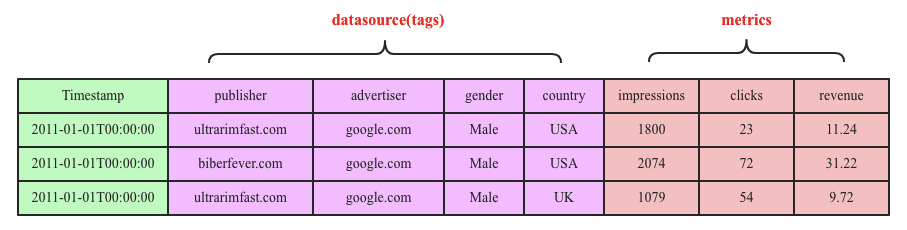
Druid是一个列式数据库,所以每一列都会独立存储,比如Timestamp列会存储在一起形成一个文件,publish列会存储在一起形成一个文件,以此类推。细心的童鞋就会说了,这样存储,依然会有数据源(tags)大量冗余的问题。针对冗余这个问题,Druid和HBase的处理方式一样,都是采用编码字典对标签值进行编码,将string类型的标签值编码成int值。但和HBase不一样的是,Druid编码是局部编码,Druid和HBase都采用LSM结构,数据先写入内存再flush到数据文件,Druid编码是文件级别的,局部编码可以有效减小对内存的巨大压力。除此之外,Druid的这种列式存储模式还有如下好处:
1. 数据存储压缩率高。每列独立存储,可以针对每列进行压缩,而且可以为每列设置对应的压缩策略,比如时间列、int、fload、double、string都可以分别进行压缩,压缩效果更好。
2. 支持多维查找。Druid为datasource的每个列分别设置了Bitmap索引,利用Bitmap索引可以有效实现多维查找,比如用户想查找20110101T00:00:00这个时间点所有发布在USA的所有广告的浏览量,可以根据country=USA在Bitmap索引中找到要找的行号,再根据行号定位待查的metrics。
然而,这样的存储模型也有一些问题:
问题一:数据依然存在冗余。和OpenTSDB一样,tags存在大量的冗余。
问题二:指定数据源的范围查找并没有OpenTSDB高效。这是因为Druid会将数据源拆开成多个标签,每个标签都走Bitmap索引,再最后使用与操作找到满足条件的行号,这个过程需要一定的开销。而OpenTSDB中直接可以根据数据源拼成rowkey,查找走B+树索引,效率必然会更高。
InfluxDB时序数据存储模型设计
相比OpenTSDB以及Druid,可能很多童鞋对InfluxDB并不特别熟悉,然而在时序数据库排行榜单上InfluxDB却是遥遥领先。InfluxDB是一款专业的时序数据库,只存储时序数据,因此在数据模型的存储上可以针对时序数据做非常多的优化工作。
为了保证写入的高效,InfluxDB也采用LSM结构,数据先写入内存,当内存容量达到一定阈值之后flush到文件。InfluxDB在时序数据模型设计方面提出了一个非常重要的概念:seriesKey,seriesKey实际上就是datasource(tags)+metric,时序数据写入内存之后按照seriesKey进行组织:


内存中实际上就是一个Map:<SeriesKey, List<Timestamp|Value>>,Map中一个SeriesKey对应一个List,List中存储时间线数据。数据进来之后根据datasource(tags)+metric拼成SeriesKey,再将Timestamp|Value组合值写入时间线数据List中。内存中的数据flush的文件后,同样会将同一个SeriesKey中的时间线数据写入同一个Block块内,即一个Block块内的数据都属于同一个数据源下的一个metric。
这种设计我们认为是将时间序列数据按照时间线挑了出来。先来看看这样设计的好处:
好处一:同一数据源的tags不再冗余存储。一个Block内的数据都共用一个SeriesKey,只需要将这个SeriesKey写入这个Block的Trailer部分就可以。大大降低了时序数据的存储量。
好处二:时间序列和value可以在同一个Block内分开独立存储,独立存储就可以对时间列以及数值列分别进行压缩。InfluxDB对时间列的存储借鉴了Beringei的压缩方式,使用delta-delta压缩方式极大的提高了压缩效率。而对Value的压缩可以针对不同的数据类型采用相同的压缩效率。
好处三:对于给定数据源以及时间范围的数据查找,可以非常高效的进行查找。这一点和OpenTSDB一样。
细心的同学可能会问了,将datasource(tags)和metric拼成SeriesKey,不是也不能实现多维查找。确实是这样,不过InfluxDB内部实现了倒排索引机制,即实现了tag到SeriesKey的映射关系,如果用户想根据某个tag查找的话,首先根据tag在倒排索引中找到对应的SeriesKey,再根据SeriesKey定位具体的时间线数据。
InfluxDB的这种存储引擎称为TSM,全称为Timestamp-Structure Merge Tree,基本原理类似于LSM。后期笔者将会对InfluxDB的数据写入、文件格式、倒排索引以及数据读取进行专题介绍。
InfluxDB可以称为真正的时序数据库,存储引擎称为TSM,基本架构类似于LSM。数据按照key组织,InfluxDB中key由维度集合加上某一个列值名构成,所有属于该维度集合加列值的时间序列数值组成的一个集合就挂在该key下。这样,维度列值就不再需要冗余存储,而且timestamp和point点可以使用列式存储,独立压缩。InfluxDB的文件格式如下图所示:
Beringei时序数据存储模型设计
Beringei是今年Facebook开源的一个时序数据库系统。InfluxDB时序数据模型设计很好地将时间序列按照数据源以及metric挑选了出来,解决了维度列值冗余存储,时间列不能有效压缩的问题。但InfluxDB没有很好的解决写入缓存压缩的问题:InfluxDB在写入内存的时候并没有压缩,而是在数据写入文件的时候进行对应压缩。我们知道时序数据最大的特点之一是最近写入的数据最热,将最近写入的数据全部放在内存可以极大提升读取效率。Beringei很好的解决了这个问题,流式压缩意味着数据写入内存之后就进行压缩,这样会使得内存中可以缓存更多的时序数据,这样对于最近数据的查询会有很大的帮助。
Beringei的时序数据模型设计与InfluxDB基本一致,也是提出类似于SeriesKey的概念,将时间线挑了出来。但和InfluxDB有两个比较大的区别:
1. 文件组织形式不同。Beringei的文件存储形式按照时间窗口组织,比如最近5分钟的数据全部写入同一个文件,这个文件分为很多block,每个block中的所有时序数据共用一个SeriesKey。Beringei文件没有索引,InfluxDB有索引。
2. Beringei目前没有倒排索引机制,因此对于多维查询并不高效。
后续笔者也会针对Beringei的数据写入、流式压缩、文件格式等进行介绍。在笔者看来,如果将Beringei和InfluxDB有效结合起来,就能够将时序数据高效存储在内存,另外数据按照维度进行组织,可以非常高效的提高数据在文件的存储效率以及查询效率,最后结合InfluxDB的倒排索引功能可以有效提高多维查询能力。
本文是时序数据库技术体系的第一篇文章,笔者主要结合OpenTSDB、Druid、InfluxDB以及Beringei这四种时序数据库分别对时序数据这种数据形式的存储模型进行了介绍。每种数据库都有自己的一套存储方式,而每种存储方式都有各自的一些优势以及缺陷,正是这些优劣式直接决定了相应时序数据库的压缩性能、读写性能。
原文:
相关阅读:
更多网易技术、产品、运营经验分享敬请关注网易社区知乎机构号: